
 C大型程序
C大型程序
# 情况
在编写 STM32 的工程文件或者需要构建更易于模块化、更易于移植的程序时,我们需要通过方法构建大型的程序,主要是通过构建.c与.h文件实现的。为了便于区分,本文将会把.c文件叫做源文件,而.h文件叫做头文件(但事实上,这两种文件都是 C 的源文件)
# 简介
这里有一个简单的 C 程序,当然是我瞎写的。功能就是通过判断输入的数是奇数还是偶数,返回一个布尔值,随后根据布尔值来进行后续计算操作:
#include <stdio.h>
#include <stdbool.h>
bool judge_odd(int num);
void calculate_odd(int oddnum);
void calculate_even(evennum);
int main()
{
int number;
scanf("%d", &number);
if (judge_odd(number) == true)
{
calculate_odd(number);
}
else if (judge_odd == false)
{
calculate_even(number);
}
return 0;
}
bool judge_odd(int num)
{
if (num % 2 == 1)
{
return true;
}
else
{
return false;
}
}
void calculate_odd(int oddnum)
{
printf("%d\n", oddnum + 1);
}
void calculate_even(evennum)
{
printf("%d\n", evennum + 2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
为了实现开头的好处,某同学就将这个程序中的功能分为了三块:
- 程序的核心:
main函数,它掌管着程序的主线剧情 - 判断区:判断一个数是否为奇数
- 计算区:对奇数或偶数进行计算
于是根据这三个区,将1个文件分割成了5个文件:main.c, judge.c, judge.h, calculate.c 与calculate.h
/*** main.c ***/
#include <stdio.h>
#include <stdbool.h>
#include "judge.h"
#include "calculate.h"
int main()
{
int number;
scanf("%d", &number);
if (judge_odd(number) == true)
{
calculate_odd(number);
}
else if (judge_odd == false)
{
calculate_even(number);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/*** judge.c ***/
include "judge.h"
bool judge_odd(int num)
{
if (num % 2 == 1)
{
return true;
}
else
{
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
/*** judge.h ***/
#include <stdbool.h>
bool judge_odd(int num);
2
3
/*** calculate.c ***/
#include "calculate.h"
void calculate_odd(int oddnum)
{
printf("%d\n", oddnum + 1);
}
void calculate_even(evennum)
{
printf("%d\n", evennum + 2);
}
2
3
4
5
6
7
8
9
10
11
12
/*** calculate.h ***/
#include <stdio.h>
void calculate_odd(int oddnum);
void calculate_even(evennum);
2
3
4
下面就来介绍一下这个同学的逻辑
# 方法
# 将程序模块化
这个就不必多说,你可以将你程序内的为了实现同一功能的函数、变量归为一类
# 分割文件
把某一类的函数与变量放进同一个文件当中。但是需要注意的是这里我们最好是把一个功能区分写为两个文件:一个是源文件,一个是头文件。
将源文件内定义的函数原型、变量声明(非变量定义)与用到的标准库全部放进其同名的头文件中,然后将这个头文件包含在这个源文件中。这么做的目的有两个:
- 方便其他模块对此模块内函数的引用,只需包含此头文件即可
- 检查同名的头文件与源文件内函数等的原型与声明有无出入,是否相同
注意
需要注意一点,就是头文件的包含方式:
#include <>形式包含的会优先在系统的头文件目录下搜寻#include ""形式包含的会优先在目前目录下搜寻
所以你自己定义的头文件最好使用#include ""的形式,且标准库严禁使用#include ""来包含
# 注意事项
# 能共享什么
通过头文件共享的主要有三大块内容:
- 函数
- 变量
- 宏定义与类型定义
# 共享变量时
在共享变量的时候,需要注意的是:在头文件中放置的是此变量的声明而非定义:
// 这是声明且定义变量
int i;
int string[2];
// 这是只声明变量
extern int i;
extern int string[];
2
3
4
5
6
在源文件中我们声明且定义变量,编译器将为变量留出其储存空间;而在头文件中我们只使用extern关键词声明变量,表明其定义在别处,编译器就会知道了有这么一个变量的名字与类型,而不会为其留出空间,直到遇到其本身
# 共享类型定义时
在共享宏定义与类型定义的时候,需要注意一件非常重要的事:其他还好,对于类型定义,如果在一个程序流程中遇到了多次,就会报错。到底是一种什么情况呢,举个例子:
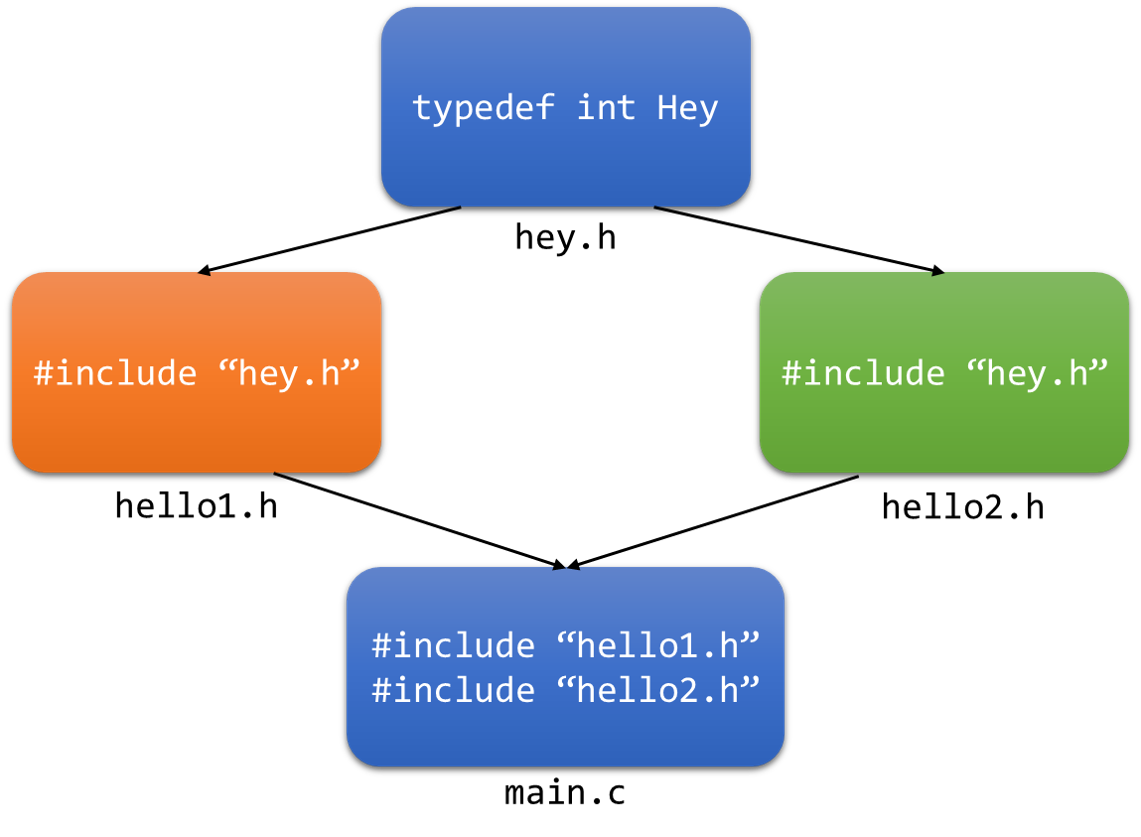
此处的main.c内这个类型定义被包含了两次,于是报错,那么解决这个问题的方法就是条件编译:
#ifndef HEY_H
#define HEY_H
typedef int Hey;
#endif
2
3
4
5
这么一来,这个头文件就会被保护得很好,第一次包含HEY_H这个宏未被声明,而再次遇到时就不会再执行第二次。这个宏的起名也最好是和头文件相同,这样就会便于记忆